为用决策树预测泰坦尼克号幸存者,做数据处理的准备工作。
方法/步骤
-
1
第一步导入pandas模块,并读取需要处理的数据。

-
2
数据导入后可以查看导入数据的基本信息
-
3
方法1:利用info()方法
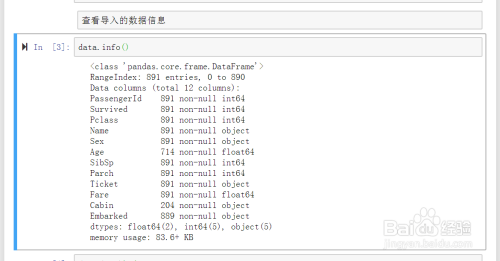
-
4
方法2:也可利用head()方法,该方法可以控制显示多少数据,可以更直观的观查看数据。

-
5
删除与模型不相关或者对模型影响不大的特征

-
6
接下来处理缺失值。
-
7
在年龄特征列中含有177个缺失值,需要将其处理。
-
8
此处用均值填充的方法处理该列的缺失值,注意并不是所有的数据都可以采用均值填充。

-
9
处理完年龄所在列的缺失值后,发现Embarked特征列中含有2个缺失值。
-
10
Embarked所在列有2个缺失值,并且数据类型为object,因此可以将该2行数据删除,对模型的影响不大。
-
11
删除数据集中的缺失值方法:dropna()默认对行操作,删除有缺失值行的数据。
-
12
但是需要注意的是:此方法是将删除后的数据返回,不会对原始数据做修改。

-
13
若希望在原始数据上直接修改,可传入inplace=True。
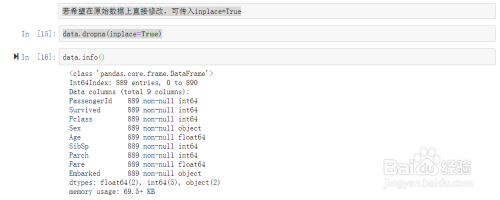
-
14
到此为止,数据集中的缺失值处理完毕。
-
15
但由于决策树处理的数据类型为数字,因此接下来需要将数据集中的非数字类型转换为数字类型。
-
16
可以利用unique()方法查看数据的分类信息。

-
17
以下是将多分类(不超过10个)的数据转换为10以内的数字的方法。


-
18
接下来处理性别这个特征所在列的数据,处理方法仍然可以利用上面的方方法处理,下面采用处理二分类数据的方法
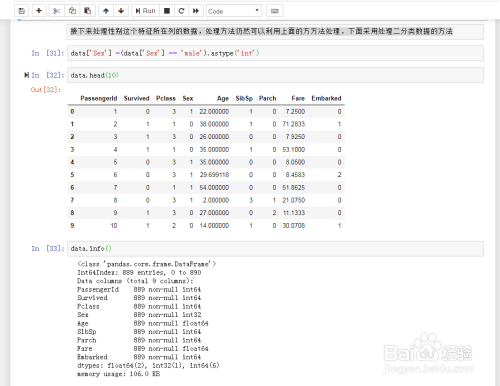
-
19
处理完成后的数据如图示:

-
20
到目前为止,决策树所需要的数据已经准备完成,可以建立决策树模型了。
END
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。
展开阅读全部

文章评论