笔者最近在测试Python GUI编程,尝试在界面程序显示文本文件或Python脚本(文件都包含中文)。然而由于两种文件编码不同,一开始在代码处理过程顾此失彼,中文部分常以乱码显示。最后终于寻得解决方法。
3Python | tk怎么浏览和打开文件
问题线索
-
1
可以知道的是,文本文件的默认编码并不是utf8。
我们打开一个文本文件,并点击另存为
-
2
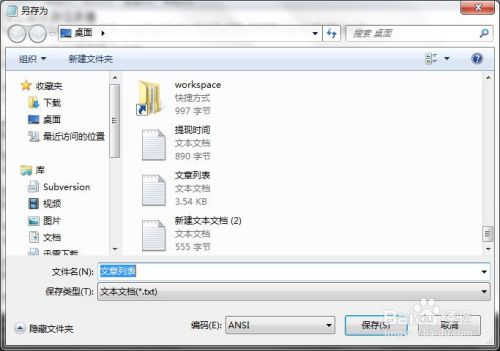
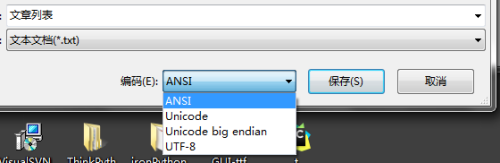
我们在新窗口的编码一栏看到默认编码是ANSI。先不管这个编码是什么编码,但是通过下拉列表我们知道,这种编码不是utf8。
 END
END
编码测试
-
1
对于Python里面的中文显示,我们常常使用utf8和gbk的编码。对于这两种编码笔者就不介绍了,总之都是专门可以处理中文的编码方式啦。
-
2
我们首先对文本文件测试了gbk解码。我们发现,此编码下文本文件内容可以正常显示,但是使用utf8解码,程序出错,抛出decodeError异常
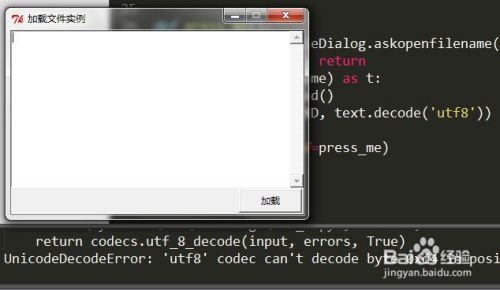
-
3
同样的,我们对Python脚本文件测试了utf8解码。我们发现,此编码下文本文件内容可以正常显示,但是使用gbk解码,中文部分出现乱码
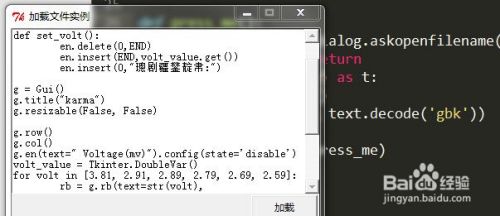
-
4
测试说明,对于文本文件需要使用gbk解码,而对于脚本文件需要utf8解码,也就是说,文本文件是gbk编码的,而脚本则是utf8
END
解决法一:异常处理
-
我们从上面的编码测试发现,文本文件在使用utf8解码时会抛出异常,所以我们在代码中可以做如下处理——也就是在异常抛出时采用gbk解码
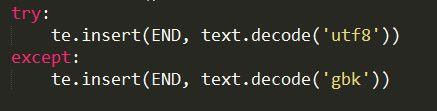
-
经过测试,发现程序可以满足两种文件正常显示
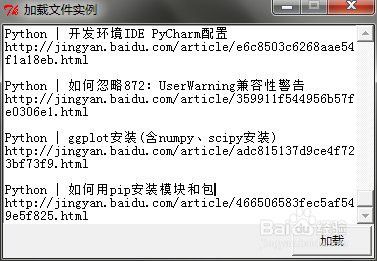 END
END
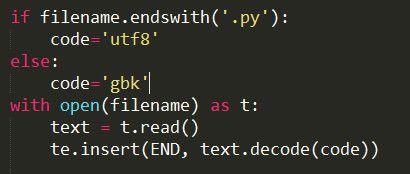
终极解法:chardet
-
1
chardet模块可以检测字符编码,应该说是类似问题的终极解决。先安装一下
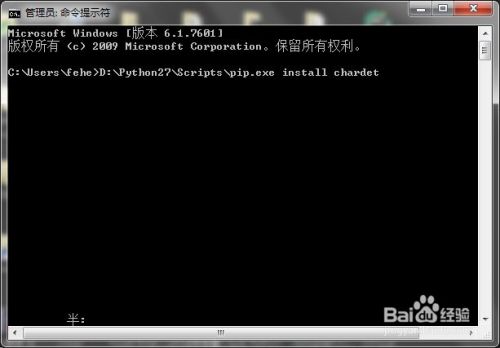
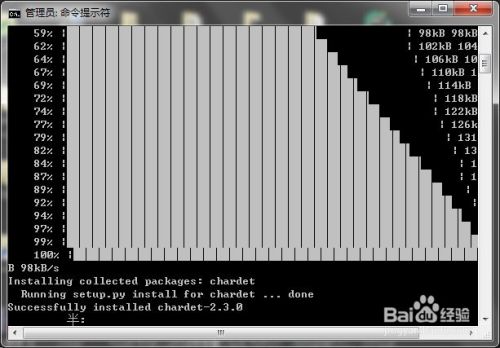
-
2
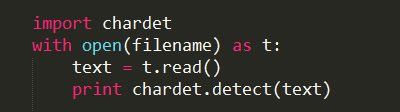
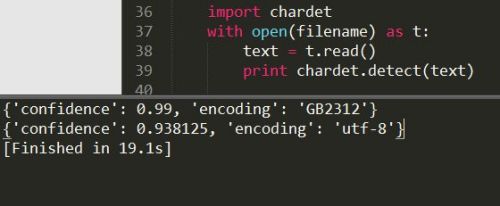
通过下面代码测试一下两种文件的编码。我们看到,通过chardet模块返回的是一个字典。字典的前一个元素是编码检查的概率,后一个是编码类型
-
3
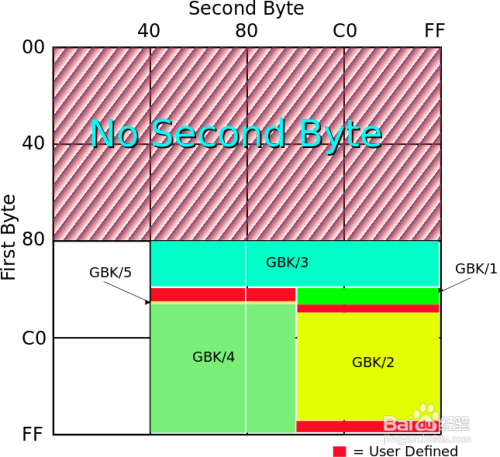
我们看到,文本文件的编码方式是GB2312,而我们上面使用gbk的解码也是可以的,那是因为gb2312是gbk的一个子集(GBK/1、GBK/2是GB2312区域)
-
4
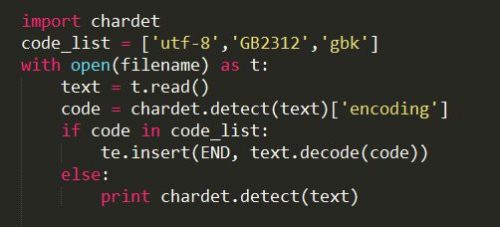
现在我们修改一下最终的代码,把这个编码问题解决掉~
 END
END

文章评论